
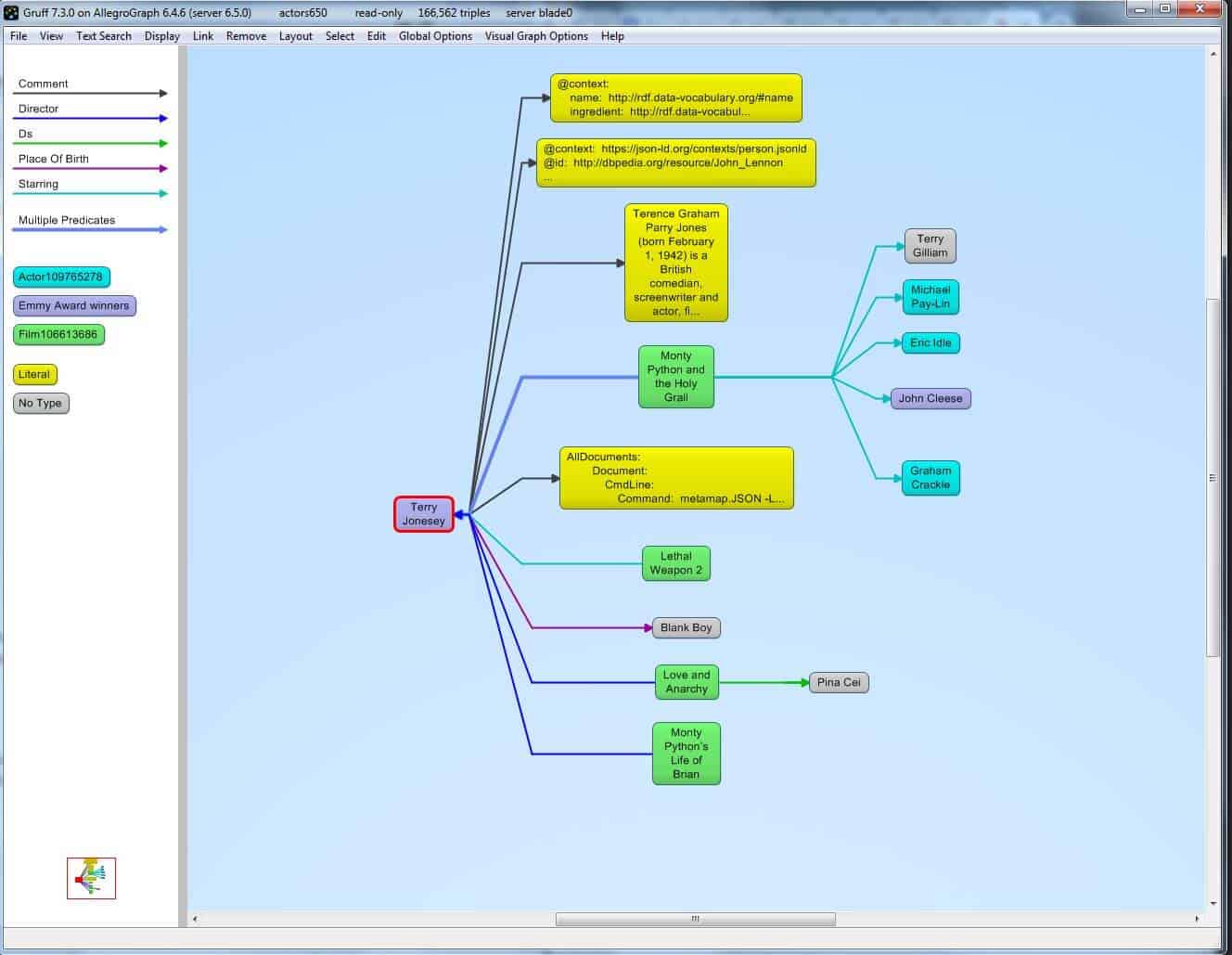




AllegroGraph - Neuro-Symbolic AI Platform
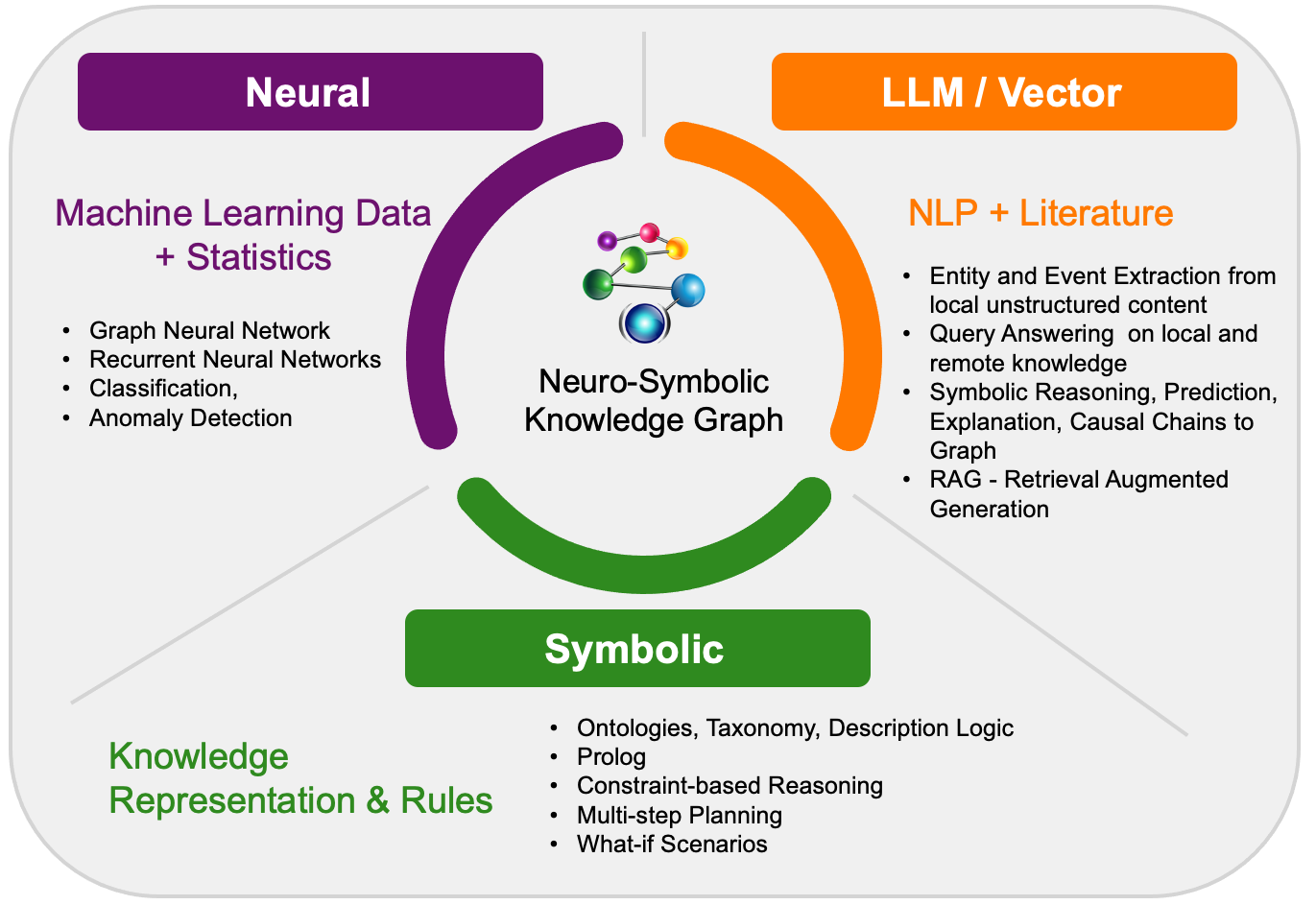
Exploring AllegroGraph v8 – Unleashing the Power of Neuro-Symbolic AI
-

Hallucination Detection using AllegroGraph (Knowledge Graph), LLM, and SerpAPI
-

FedShard for Entity-Event Knowledge Graphs
-
Gruff in the Browser Demonstration
-

AllegroGraph - The Most Secure Knowledge Graph Platform
-
JSON LD and SHACL for Knowledge Graphs
-
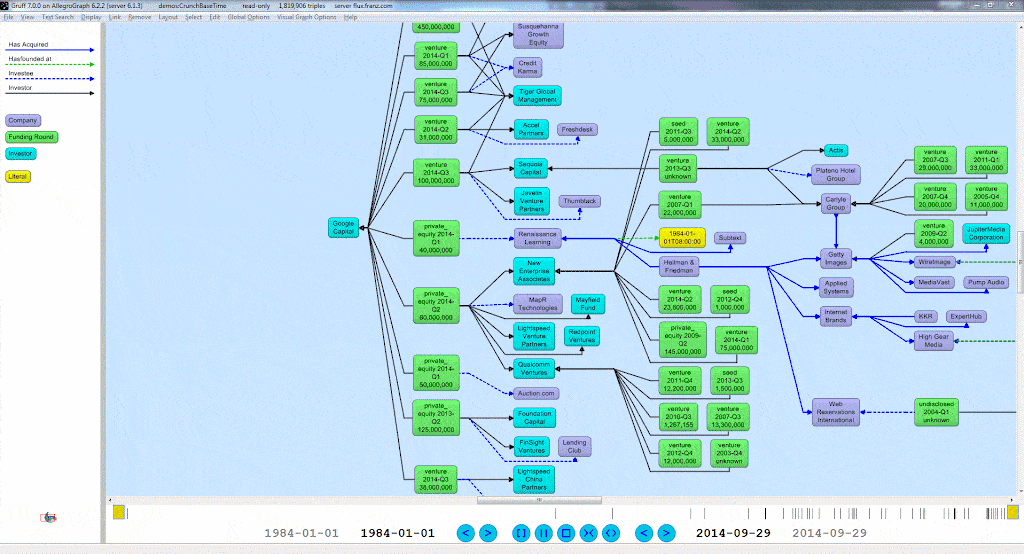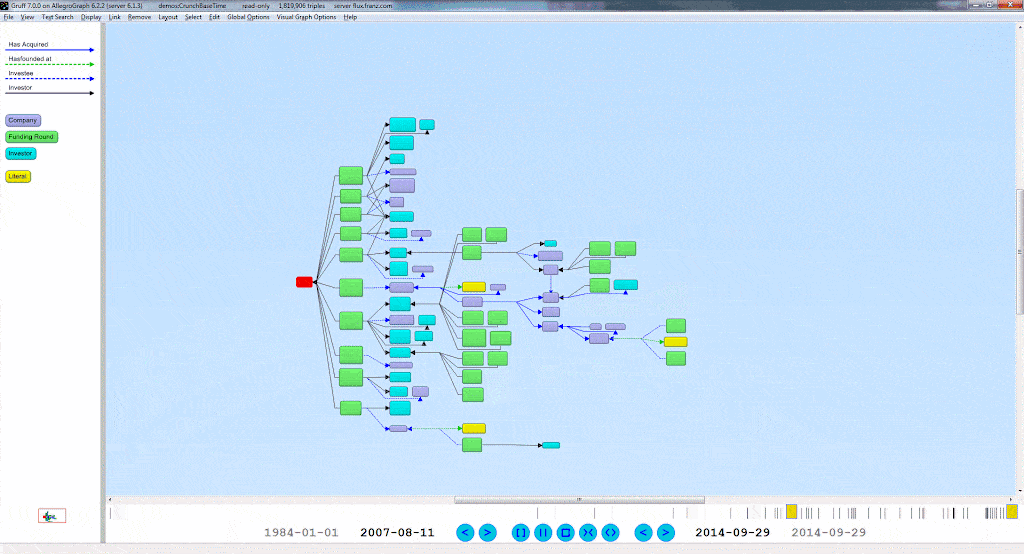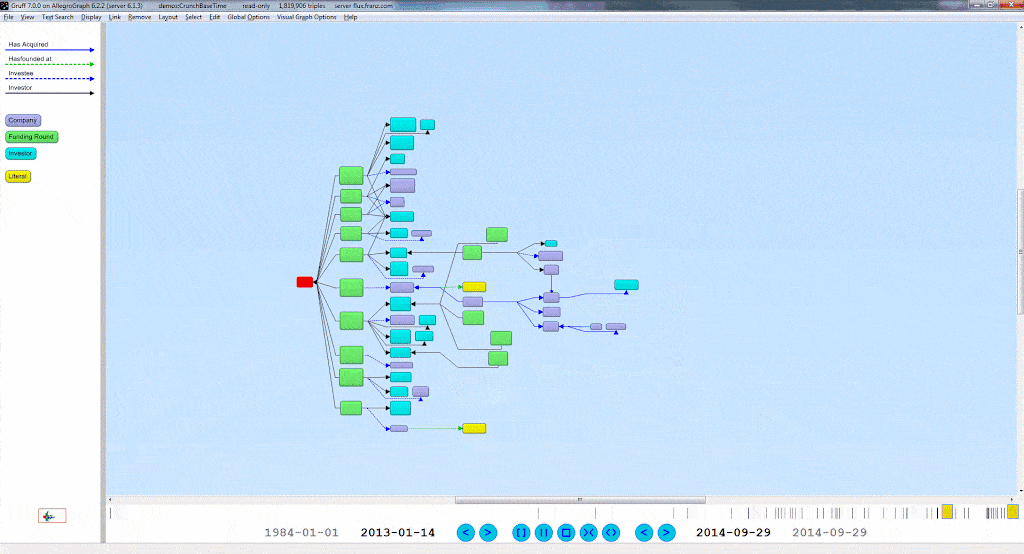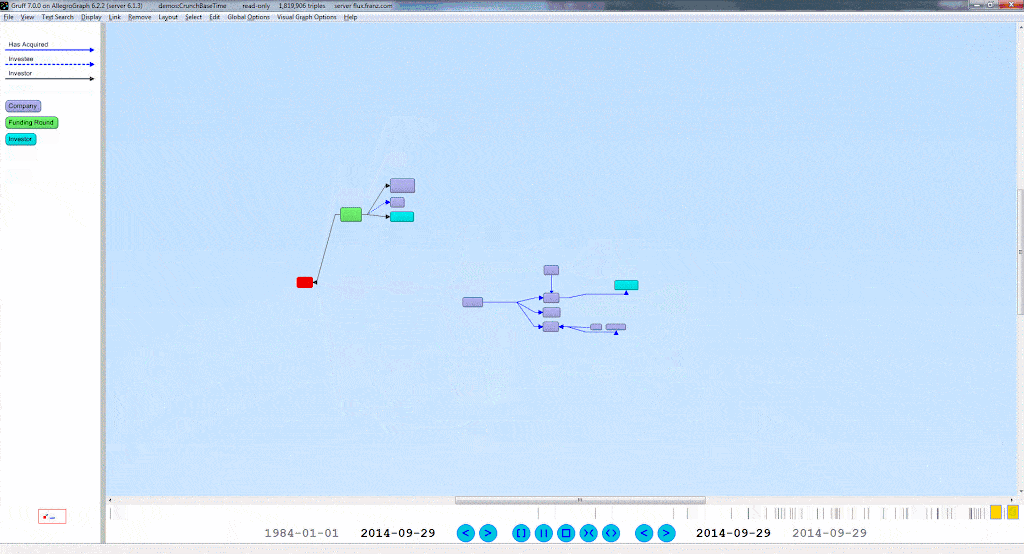
A Time Machine for your Graph
News and Events




-

Knowledge Graph Technology Showcase Honest Review
-

Webinar (Recording) – Exploring AllegroGraph v8 – Unleashing the Power of Neuro-Symbolic AI